The explore package offers a simplified way to use machine learning to understand and explain patterns in the data.
-
explain_tree()creates a decision tree. The target can be binary, categorical or numerical -
explain_forest()creates a random forest. The target can be binary, categorical or numerical -
explain_xgboost()creates a random forest. The target must be binary (0/1, FALSE/TRUE) -
explain_logreg()creates a logistic regression. The target must be binary -
balance_target()to balance a target -
weight_target()to create weights for the decision tree
We use synthetic data in this example
library(dplyr)
library(explore)
data <- create_data_buy(obs = 1000)
glimpse(data)
#> Rows: 1,000
#> Columns: 13
#> $ period <int> 202012, 202012, 202012, 202012, 202012, 202012, 202012…
#> $ buy <int> 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, …
#> $ age <int> 39, 57, 55, 66, 71, 44, 64, 51, 70, 44, 58, 47, 68, 71…
#> $ city_ind <int> 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, …
#> $ female_ind <int> 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, …
#> $ fixedvoice_ind <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, …
#> $ fixeddata_ind <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
#> $ fixedtv_ind <int> 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, …
#> $ mobilevoice_ind <int> 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, …
#> $ mobiledata_prd <chr> "NO", "NO", "MOBILE STICK", "NO", "BUSINESS", "BUSINES…
#> $ bbi_speed_ind <int> 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, …
#> $ bbi_usg_gb <int> 77, 49, 53, 44, 55, 93, 50, 64, 63, 87, 45, 45, 70, 79…
#> $ hh_single <int> 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, …Explain / Model
Decision Tree
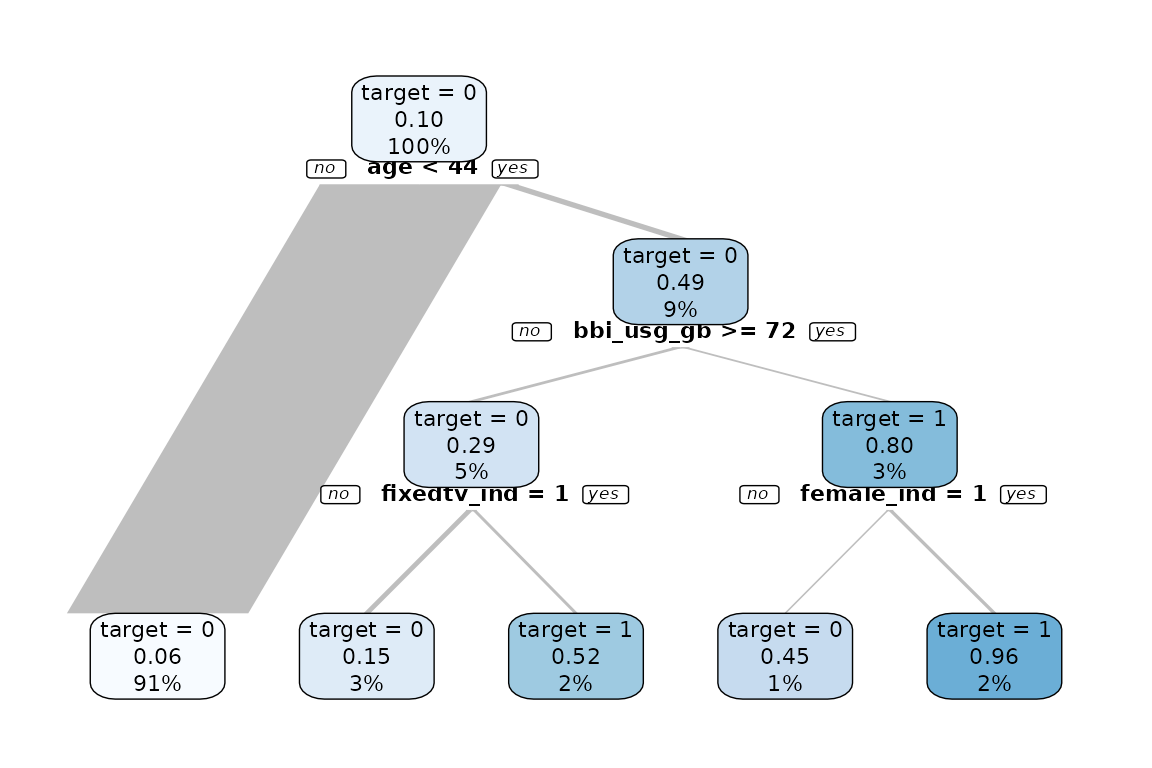
data %>% explain_tree(target = buy)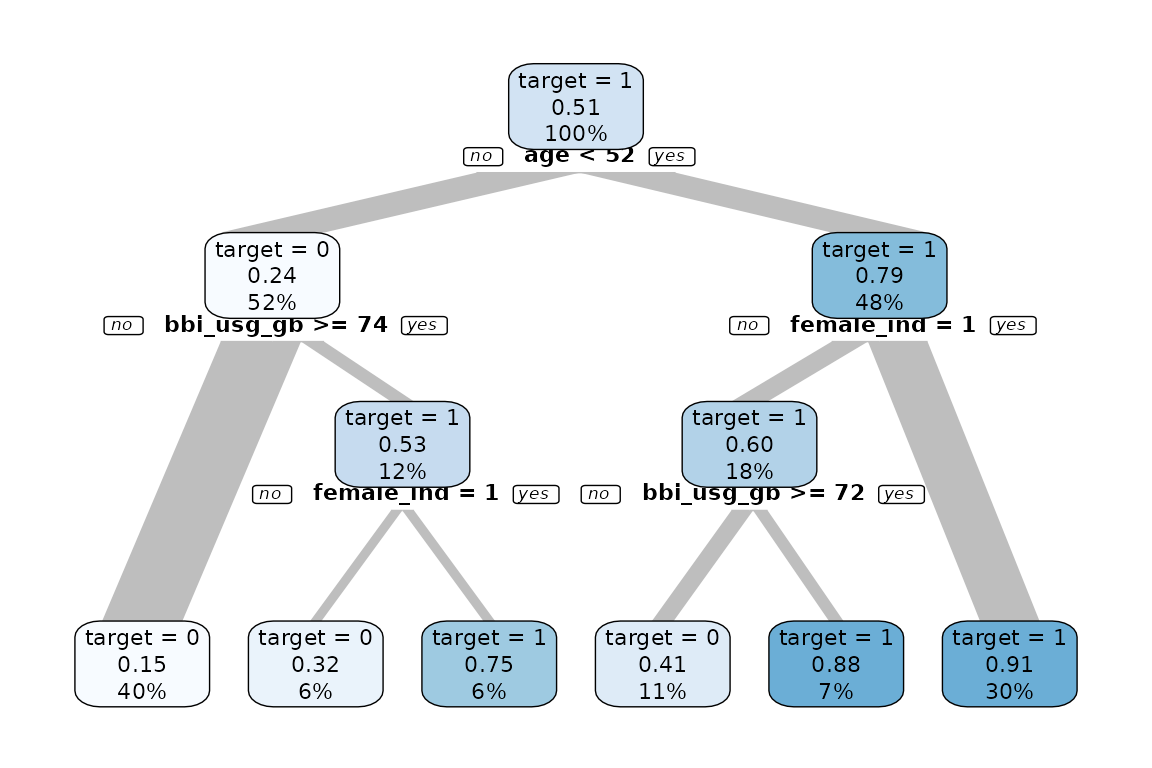
data %>% explain_tree(target = mobiledata_prd)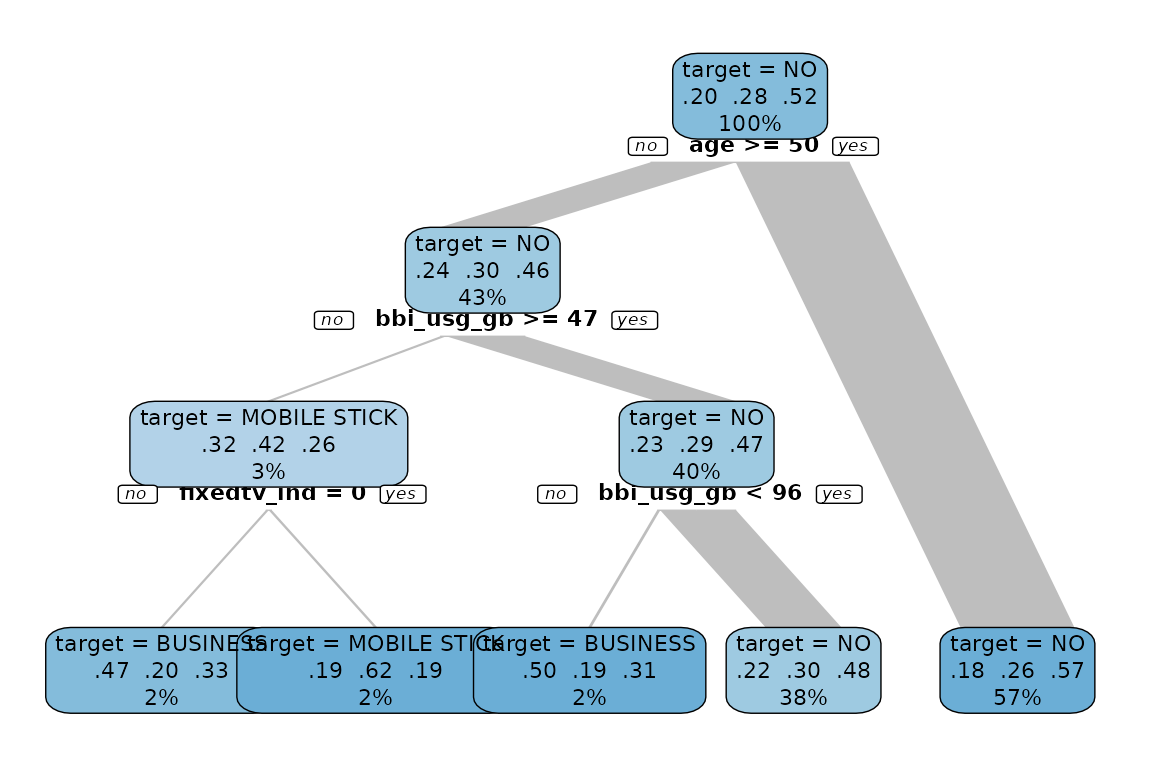
data %>% explain_tree(target = age)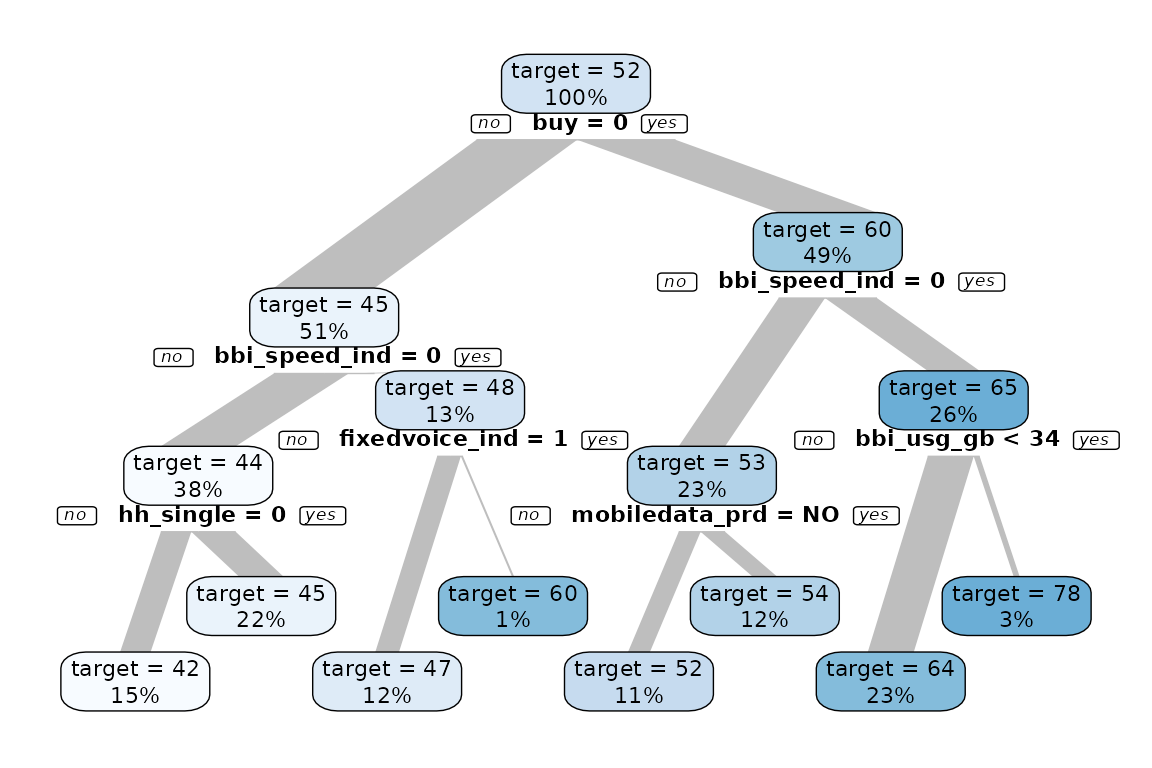
Random Forest
data %>% explain_forest(target = buy, ntree = 100)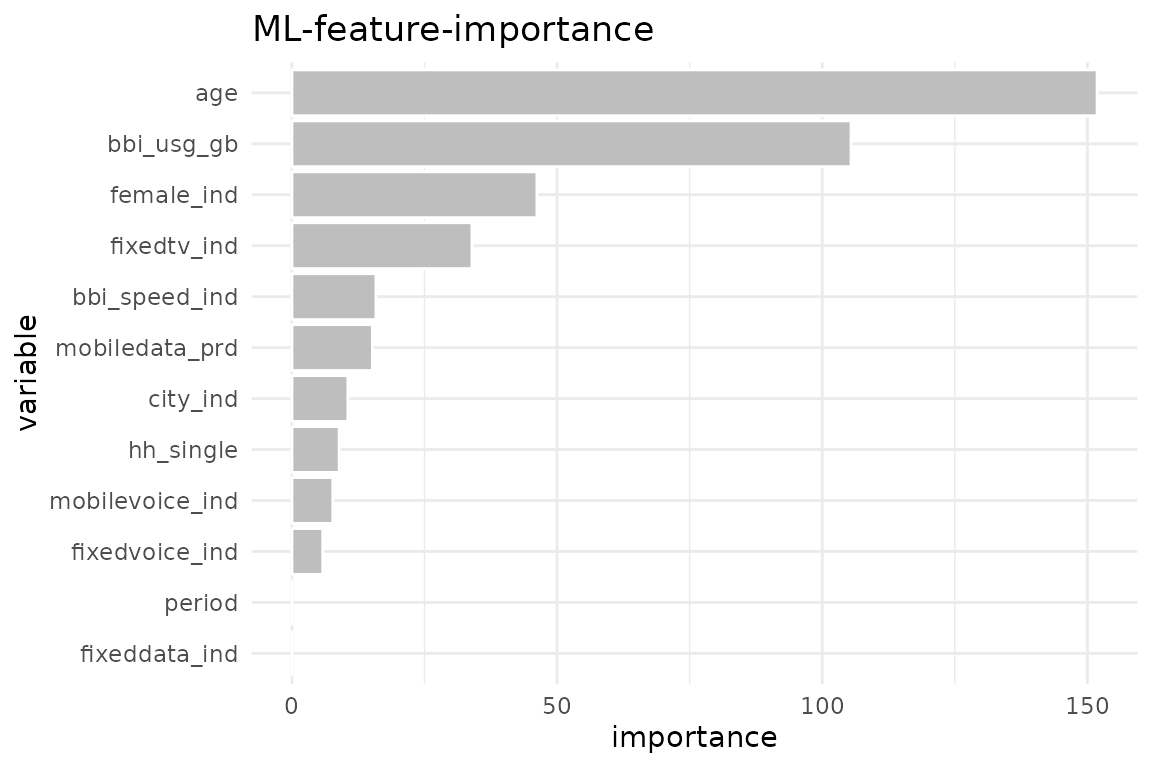
To get the model itself as output you can use the parameter
out = "model or out = all to get all (feature
importance as plot and table, trained model). To use the model for a
prediction, you can use predict_target()
XGBoost
As XGBoost only accepts numeric variables, we use
drop_var_not_numeric() to drop mobile_data_prd
as it is not a numeric variable. An alternative would be to convert the
non numeric variables into numeric.
data %>%
drop_var_not_numeric() |>
explain_xgboost(target = buy)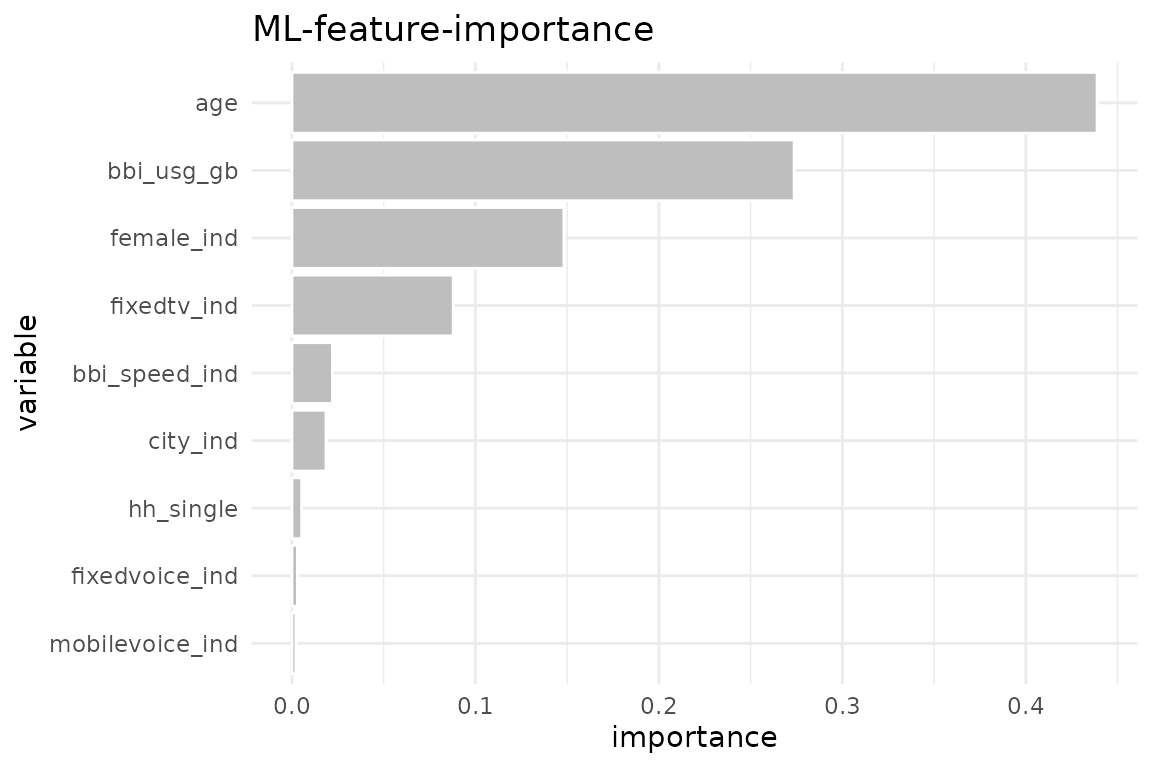
Use parameter out = "all" to get more details about the
training
train <- data %>%
drop_var_not_numeric() |>
explain_xgboost(target = buy, out = "all")
train$importance
#> variable gain cover frequency importance
#> <char> <num> <num> <num> <num>
#> 1: age 0.480076565 0.346517287 0.30325098 0.480076565
#> 2: bbi_usg_gb 0.263936257 0.306661425 0.31781534 0.263936257
#> 3: female_ind 0.133861444 0.138796555 0.12197659 0.133861444
#> 4: fixedtv_ind 0.082409865 0.106854333 0.10221066 0.082409865
#> 5: city_ind 0.020369882 0.051517918 0.05539662 0.020369882
#> 6: bbi_speed_ind 0.010279095 0.020894635 0.03276983 0.010279095
#> 7: hh_single 0.005200283 0.014226769 0.03250975 0.005200283
#> 8: mobilevoice_ind 0.002025957 0.006488770 0.01742523 0.002025957
#> 9: fixedvoice_ind 0.001840650 0.008042308 0.01664499 0.001840650
train$tune_plot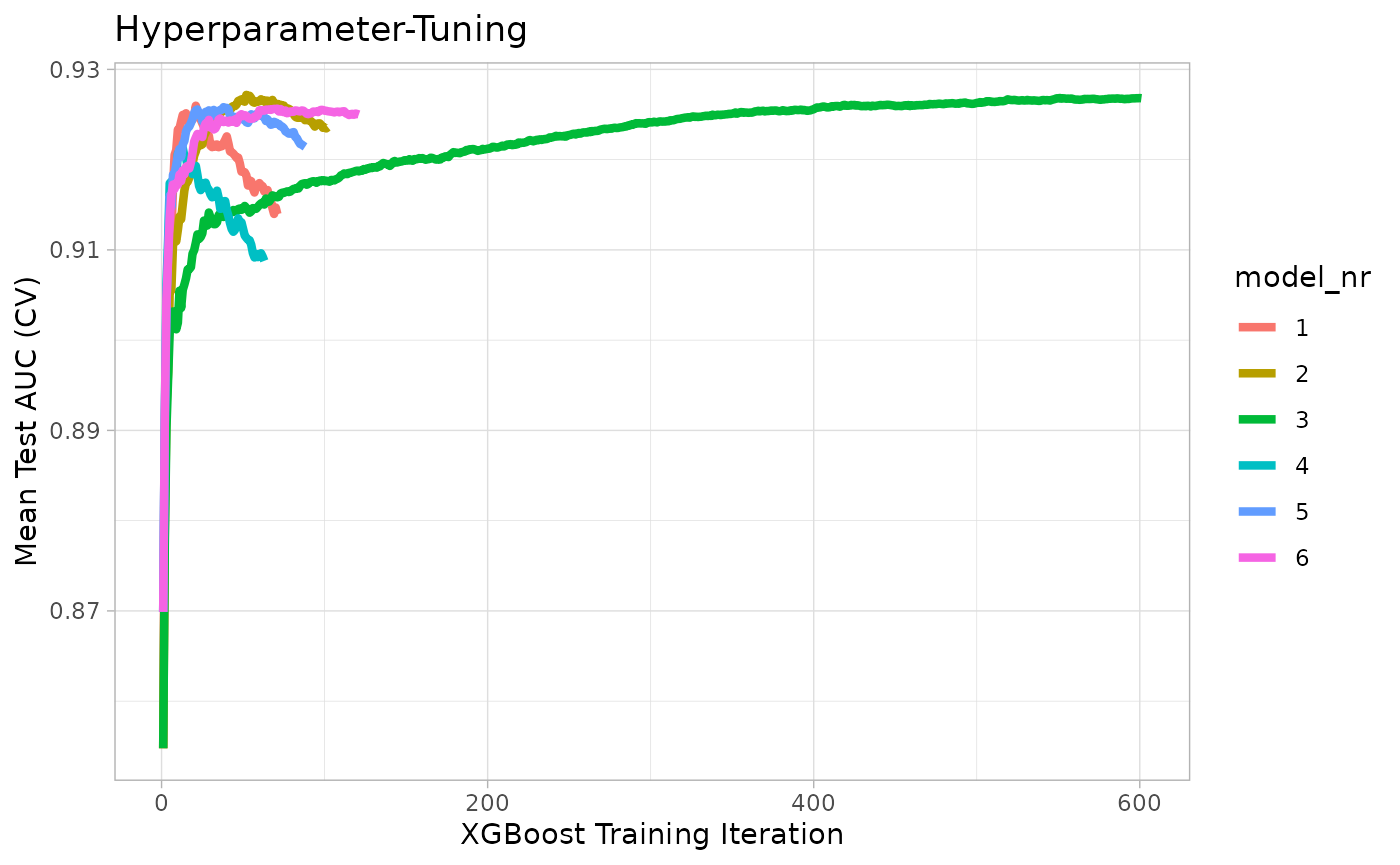
train$tune_data
#> model_nr eta max_depth runtime iter train_auc_mean test_auc_mean
#> <int> <num> <num> <difftime> <int> <num> <num>
#> 1: 1 0.30 3 0 mins 29 0.9670353 0.9229369
#> 2: 2 0.10 3 0 mins 54 0.9585660 0.9259053
#> 3: 3 0.01 3 0 mins 591 0.9602903 0.9265414
#> 4: 4 0.30 5 0 mins 12 0.9738282 0.9218968
#> 5: 5 0.10 5 0 mins 21 0.9674193 0.9250532
#> 6: 6 0.01 5 0 mins 25 0.9535213 0.9242371To use the model for a prediction, you can use
predict_target()
Logistic Regression
data %>% explain_logreg(target = buy)
#> # A tibble: 6 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 5.87 0.544 10.8 3.88e-27
#> 2 age -0.146 0.0106 -13.8 3.49e-43
#> 3 city_ind 0.711 0.183 3.89 1.02e- 4
#> 4 female_ind 1.75 0.186 9.38 6.91e-21
#> 5 fixedtv_ind 1.51 0.190 7.93 2.14e-15
#> 6 bbi_usg_gb -0.0000724 0.0000904 -0.801 4.23e- 1Balance Target
If you have a data set with a very unbalanced target (in this case
only 5% of all observations have buy == 1) it may be
difficult to create a decision tree.
data <- create_data_buy(obs = 2000, target1_prob = 0.05)
data %>% describe(buy)
#> variable = buy
#> type = integer
#> na = 0 of 2 000 (0%)
#> unique = 2
#> 0 = 1 899 (95%)
#> 1 = 101 (5.1%)It may help to balance the target before growing the decision tree
(or use weighs as alternative). In this example we down sample the data
so buy has 10% of target == 1.
data %>%
balance_target(target = buy, min_prop = 0.10) %>%
explain_tree(target = buy)